
Image Source – https://sungsoo.github.io/
In the rapidly changing world of data-driven decision-making, obtaining top-quality data is the ultimate goal for modern businesses and organizations. Leveraging data for insights and innovation has revolutionized industries, enabling companies to thrive in a data-focused era. Yet, democratizing data, ensuring universal access, remains a challenge due to issues like privacy concerns, data silos, and scarcity. Synthetic data generation emerges as a transformative technology, reshaping our perspective on data access, privacy, and innovation.
The Data Conundrum: Accessibility vs. Privacy
Data, often described as the “new oil,” holds immense potential, but it also poses significant challenges. Balancing the need for data accessibility with the imperative of protecting individual privacy is a delicate tightrope walk. Traditional data-sharing practices often involve cumbersome legal processes, data anonymization, and painstaking negotiations. This results in data hoarding, where companies guard their datasets like a dragon guarding its treasure.
Synthetic Data: A New Hope
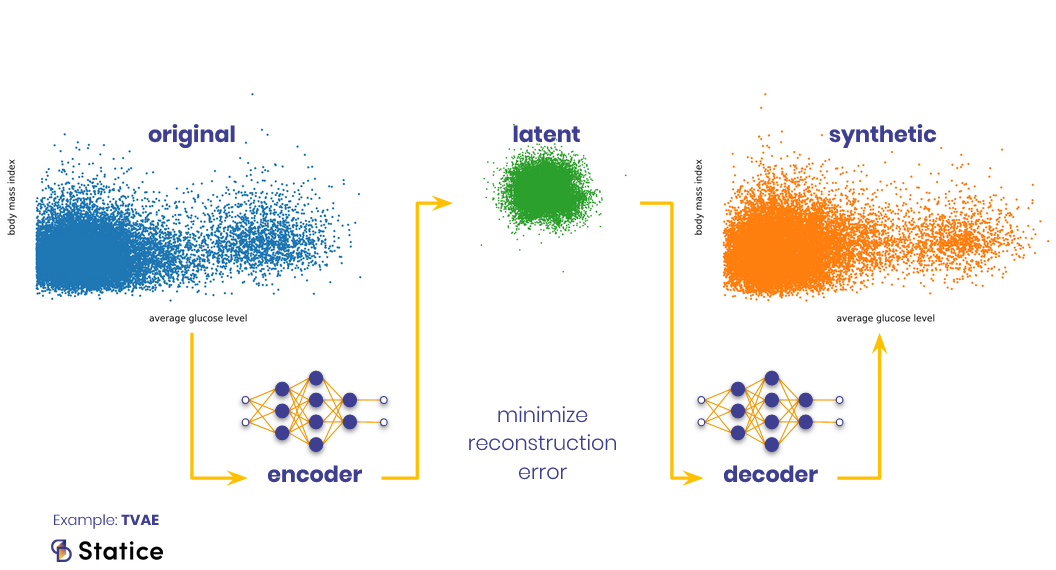
Synthetic data generation has emerged as a powerful solution to the data conundrum. At its core, synthetic data is artificially generated data that mimics the statistical properties of real data while containing no personally identifiable information (PII). It allows organizations to create datasets that are both useful and privacy-compliant, breaking down the barriers to data access and democratizing its usage.
Imagine a scenario where a healthcare organization needs to develop a machine learning model to predict disease outbreaks. Instead of dealing with sensitive patient records, they can generate synthetic data that accurately mirrors real-world health data. This synthetic dataset preserves privacy while enabling groundbreaking research.
The Magic of Synthetic Data Generation
1. Privacy Preservation: One of the most significant advantages of synthetic data is its ability to protect privacy. With the rise of data breaches and privacy regulations like GDPR and CCPA, companies are under increased pressure to safeguard sensitive information. Synthetic data ensures that no actual personal data is exposed while still providing valuable insights.
2. Overcoming Data Scarcity: In some industries, obtaining real data can be challenging due to rarity or confidentiality issues. Synthetic data fills this gap by creating data on demand. For example, autonomous vehicle companies can simulate countless hours of driving scenarios to train their AI algorithms without relying solely on real-world data.
3. Data Diversity: Synthetic data allows organizations to diversify their datasets, reducing the risk of bias in AI models. By generating data from a wide range of sources and demographics, it can mitigate the biases often found in real-world data.
Synthetic Data Generation Techniques
Synthetic data generation techniques rely on a blend of statistical methods, machine learning, and creativity to craft datasets that are both informative and privacy-compliant. Here are some key techniques:
- Generative Adversarial Networks (GANs): GANs are a pair of neural networks—generator and discriminator—engaged in a creative duel. The generator crafts synthetic data, while the discriminator evaluates its authenticity. Over time, this competition results in the generation of increasingly realistic data.
- Differential Privacy: This technique adds controlled noise to real data, making it challenging to identify specific individuals while preserving overall data trends and patterns.
- Data Augmentation: By introducing variations, transformations, or perturbations to real data, synthetic data can be created to expand the diversity of the dataset without disclosing sensitive information.
Applications of Synthetic Data Generation
The applications of synthetic data generation are as diverse as the datasets it can create. Here are a few compelling examples:
1. Finance: Banks can use synthetic data to test their fraud detection algorithms without using real customer data, thus reducing security risks.
2. Retail: E-commerce companies can simulate customer behavior to optimize product recommendations and inventory management.
3. Healthcare: Medical researchers can develop and validate AI-driven diagnostic tools without exposing sensitive patient information.
4. Transportation: Self-driving car companies can generate synthetic road data to train and test their autonomous vehicles, ensuring safety without real-world risks.
Challenges and Limitations
While synthetic data generation offers immense potential, it’s not without its challenges:
1. Realism: Generating truly representative synthetic data can be challenging. If the synthetic data doesn’t accurately reflect real-world scenarios, it may lead to flawed conclusions.
2. Complexity: Creating high-quality synthetic data requires advanced machine learning techniques and substantial computational resources.
3. Ethical Considerations: The use of synthetic data should also be governed by ethical principles to prevent misuse or manipulation.
Conclusion
Synthetic data generation is transforming the data landscape by democratizing access, preserving privacy, and unlocking the full potential of data-driven insights. It’s a game-changer for businesses, enabling data leverage without compromising privacy or facing data scarcity. As technology advances, synthetic data generation will play a growing role in our data-driven future, leveling the playing field, and making data a universal resource.
In the ever-evolving data revolution, synthetic data generation is the key to democratizing data, breaking down the barriers, and allowing innovation to flourish in a privacy-conscious world.